登录 Ambari 之后,点击按钮“Launch Install Wizard”,就可以开始创建属于自己的大数据平台。
第一步,命名集群的名字。本环境为 bigdata。
第二步,选择一个 Stack,这个 Stack 相当于一个 Hadoop 生态圈软件的集合。Stack 的版本越高,里面的软件版本也就越高。这里我们选择 HDP2.2,里面的对应的 Hadoop 版本为 2.6.x。
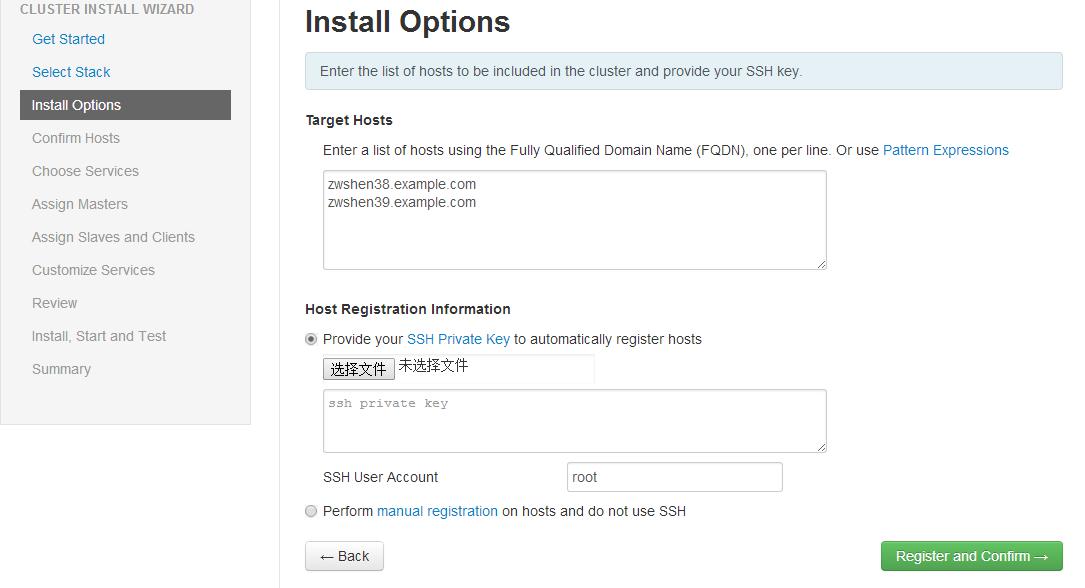
第三步,指定 Agent 机器(如果配置了域,必须包含完整域名,例如本文环境的域为 example.com),这些机器会被安装 Hadoop 等软件包。还记得在安装章节中提到的 SSH 无密码登陆吗,这里需要指定当时在 Ambari Server 机器生成的私钥(ssh-keygen 生成的,公钥已经拷贝到 Ambari Agent 的机器,具体的 SSH 无密码登录配置,可以在网上很容易找到配置方法,不在此赘述)。另外不要选择“Perform manual registration on hosts and do not use SSH“。因为我们需要 Ambari Server 自动去安装 Ambari Agent。具体参见下图示例。
图 1. 安装配置页面
第四步,Ambari Server 会自动安装 Ambari Agent 到刚才指定的机器列表。安装完成后,Agent 会向 Ambari Server 注册。成功注册后,就可以继续 Next 到下一步。
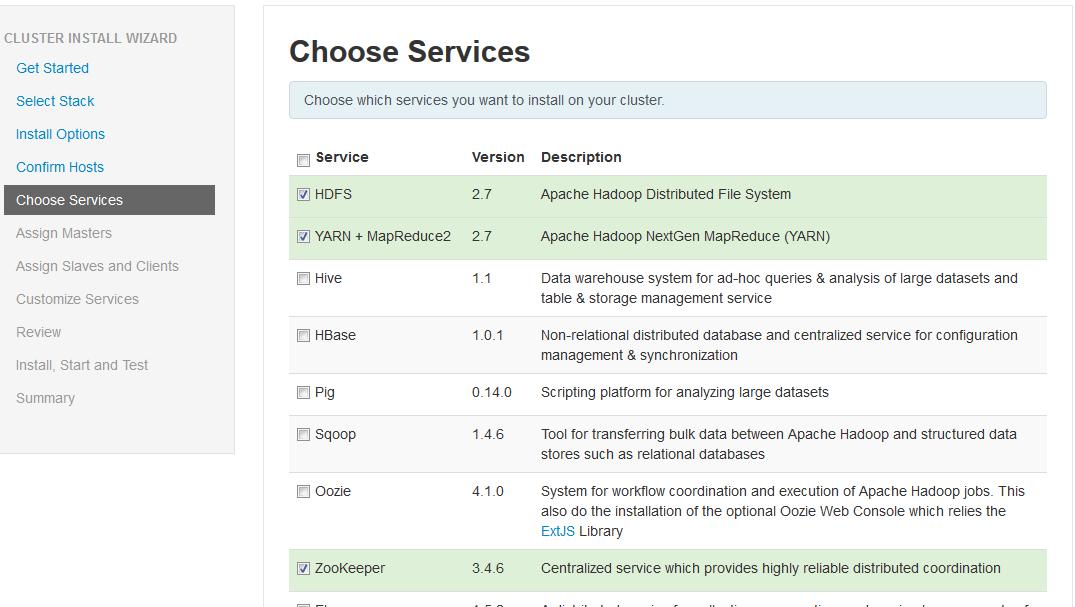
第五步,这里我们终于看到跟 Hadoop 有关的名词了。在这一步,我们需要选择要安装的软件名称。本文环境选择了 HDFS,YARN + MapReduce2,Zoopkeeper,Storm 以及 Spark。选的越多,就会需要越多的机器内存。选择之后就可以继续下一步了。这里需要注意某些 Service 是有依赖关系的。如果您选了一个需要依赖其他 Service 的一个 Service,Ambari 会提醒安装对应依赖的 Service。参见下图。
图 2. Service 选择页面
第六步和第七步,分别是选择安装软件所指定的 Master 机器和 Slave 机器,以及 Client 机器。这里使用默认选择即可(真正在生产环境中,需要根据具体的机器配置选择)。
第八步,就是 Service 的配置。绝大部分配置已经有默认值,不需要修改。初学者,如果不需要进行调优是可以直接使用默认配置的。有些 Service 会有一些必须的手工配置项,则必须手动输入,才可以下一步。本文环境直接使用默认配置。
第九步,Ambari 会总结一个安装列表,供用户审阅。这里没问题,就直接下一步。
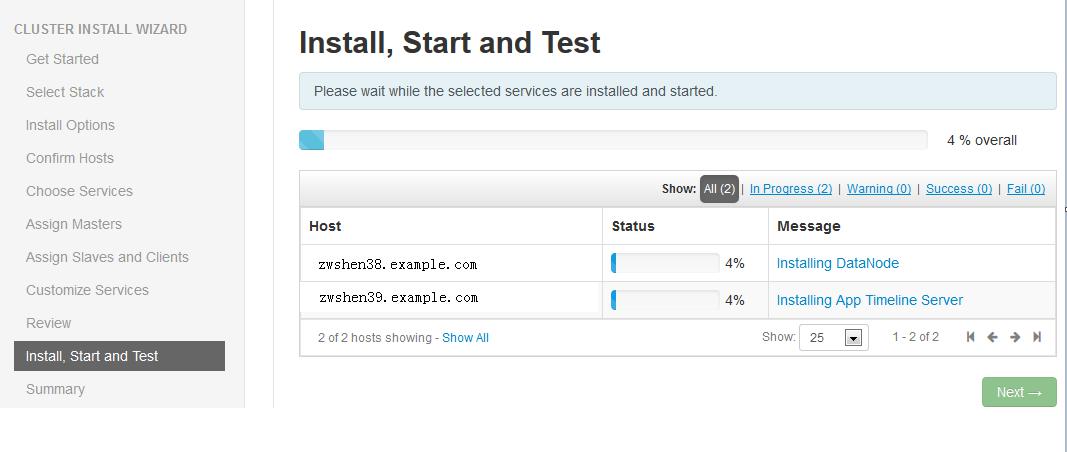
第十步,Ambari 会开始安装选择的 Service 到 Ambari Agent 的机器(如下图)。这里可能需要等好一会,因为都是在线安装。安装完成之后,Ambari 就会启动这些 Service。
图 3. Service 的安装进度
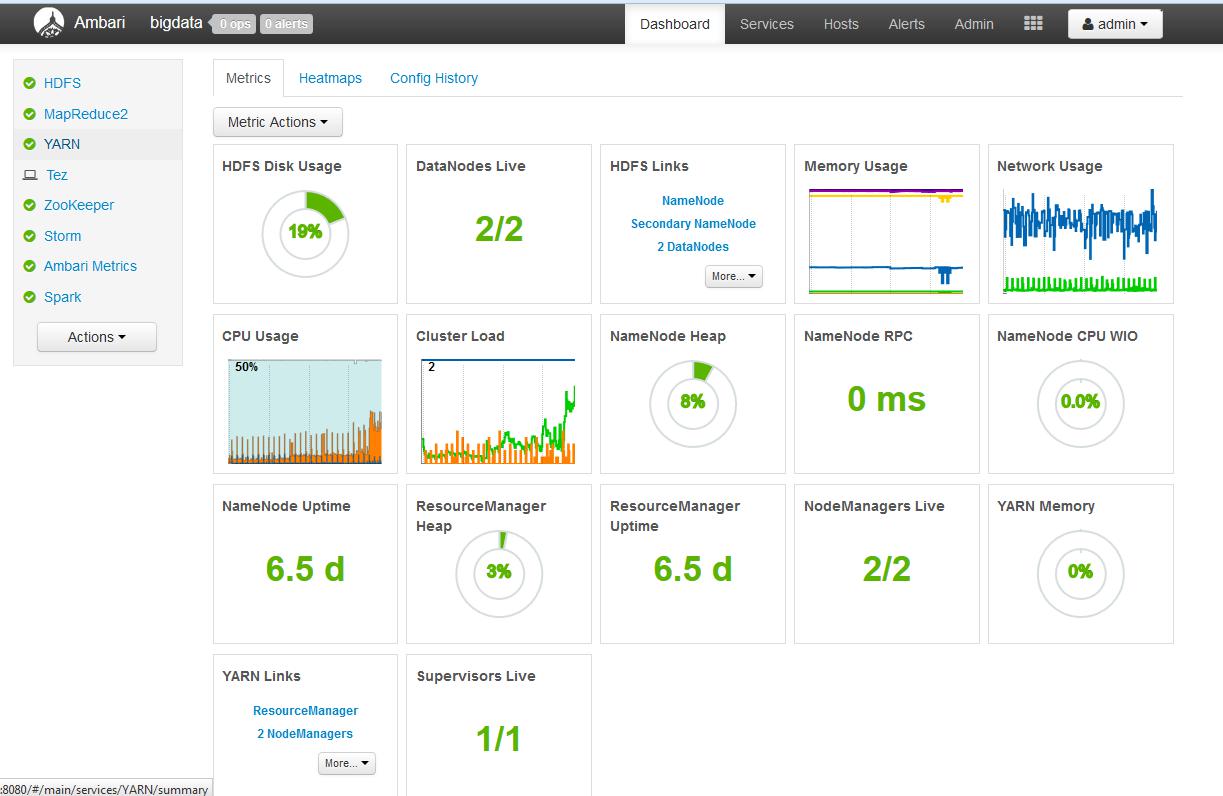
安装完成之后,就可以查看 Ambari 的 Dashboard 了。例如下图。
图 4. Ambari 的 Dashboard 页面
至此,您专属的 bigdata 集群已经安装完成。